Learning English and Software Testing

ダイの大冒険という漫画が大好きなbun913です。
みなさんは深さ優先探索に泣いたことがありますか?私はあります。
このブログはもともと「競技プログラミングの参加メモとか壁にでも話してろよ!(意訳)」という意見を見かけて、「ほんなら自分でブログ作ったるわい!」というのもきっかけで作り始めました。
今回は、キーエンスプログラミングコンテスト2023夏(AtCoder Beginner Contest 315) - AtCoderに参加し、コンテスト中にA,B,Cの問題をコンテスト中に解くことができたので、その時の気持ちを思い返しつつ次回へのゆる反省に繋げたいと思います。
A - tcdr
文字列から特定の文字をのぞいた結果を出力せよという類の問題ですね。
特にいうこともないのですが、配列(リスト)の方が扱いやすいかな?というお気持ちでリストとして受け取ってからフィルターをかけて解きました。
S = list(input())
no_use = set(['a', 'i', 'u', 'e', 'o'])
f = filter(lambda x: x not in no_use, S)
print(*f, sep="")
B - The Middle Day
これは計算すれば少ない計算量で解けそうだなと思いましたが、MもDも制約が緩いので愚直に数え上げるのが間違い少なそうだなと思いました。
ということで以下のように解くことに決めました。
- 問題文に書かれた通り1年の中央の日までの日数を計算
- あとは各月に書かれている数字を愚直にforで1日ずつインクリメントしていく
- 求めていた中央の日数に到達したら出力する
このとおりに実装したら、以下のようなコードになりました。
M = int(input())
days = list(map(int, input().split()))
sum = sum(days)
# 中央の値
central = (sum+1) // 2
cur = 0
for i in range(M):
day_cnt = days[i]
month_day = 0
for cnt in range(1, day_cnt+1):
cur += 1
month_day += 1
if cur == central:
print(i+1, month_day)
C - Flavors
アイスクリームを2個選んで、最も満足度が高くなるものを考えます。
問題文をみて、要するに同じ味のアイスから2つを選ぶ or 違う味のアイスから2つ選ぶだけしかないよなぁ。と思いました。
また、同じ味のアイスから選ぶパターンでも上位2個のアイスしか使わない から 各味のアイスの上位2種だけ保持すれば良さそう という気づきを得ることができました。
ということで次の方針で問題を解くことにしました。
- 各味の上位2種を辞書で保持する
{"からあげ味": [100,99]}のような形です- 辞書にしたのは味が1から始まるとも限らないし、わざわざ二次元配列で不必要に領域を確保するのも勿体無いなと思ったためです
- 同じ味から2種類選んだ場合の満足度の最大値を求める(A)
- ただし、そもそも1種類しかないパターンもあるので注意
- 違う味から2種類選んだ場合の満足度の最大値を求める(B)
- AとBの最大値を出力する
最終的に以下のような実装になりました。
N = int(input())
F = []
S = []
memo = {}
for _ in range(N):
f, s = map(int, input().split())
F.append(f)
S.append(s)
if f in memo:
memo[f].append(s)
memo[f].sort(reverse=True)
# 2種だけ持つ
memo[f] = memo[f][:2]
continue
memo[f] = [s]
# 1: 同じ味から2つ選んだ場合の最大
cand1 = -1
for k, v in memo.items():
if len(v) < 2:
continue
cand1 = max(cand1, v[0] + v[1] // 2)
# 1種類しかない場合はここで終了
if len(set(F)) == 1:
print(cand1)
exit()
# 2: 違う味から2つ選んだ場合の最大値
cand2 = -1
number1_list = [lis[0] for lis in memo.values()]
number1_list.sort(reverse=True)
cand2 = number1_list[0] + number1_list[1]
print(max(cand1, cand2))
E - Prerequisites
D問題をぱっとみて「うーん。これは解けないww」となったので、こちらを実装していました。
結論からいうとコンテスト中には解けずに、コンテスト終了後に解けたので、とても悔しかった問題です。
コンテスト中のお気持ちと実装方針を立てるまで
大体以下のような感じで考察し、実装方針を立てていました。
- 各書籍に依存性があって
node_modulesみたいやなww - つまり木構造として表せそうだ
- こんな感じかな

- で、今回読む必要のある順番から出力せよって書いてあるな
- だから、木構造で言えば一番下のノードから上に向かって進む必要がありそうだな
- こんなイメージか
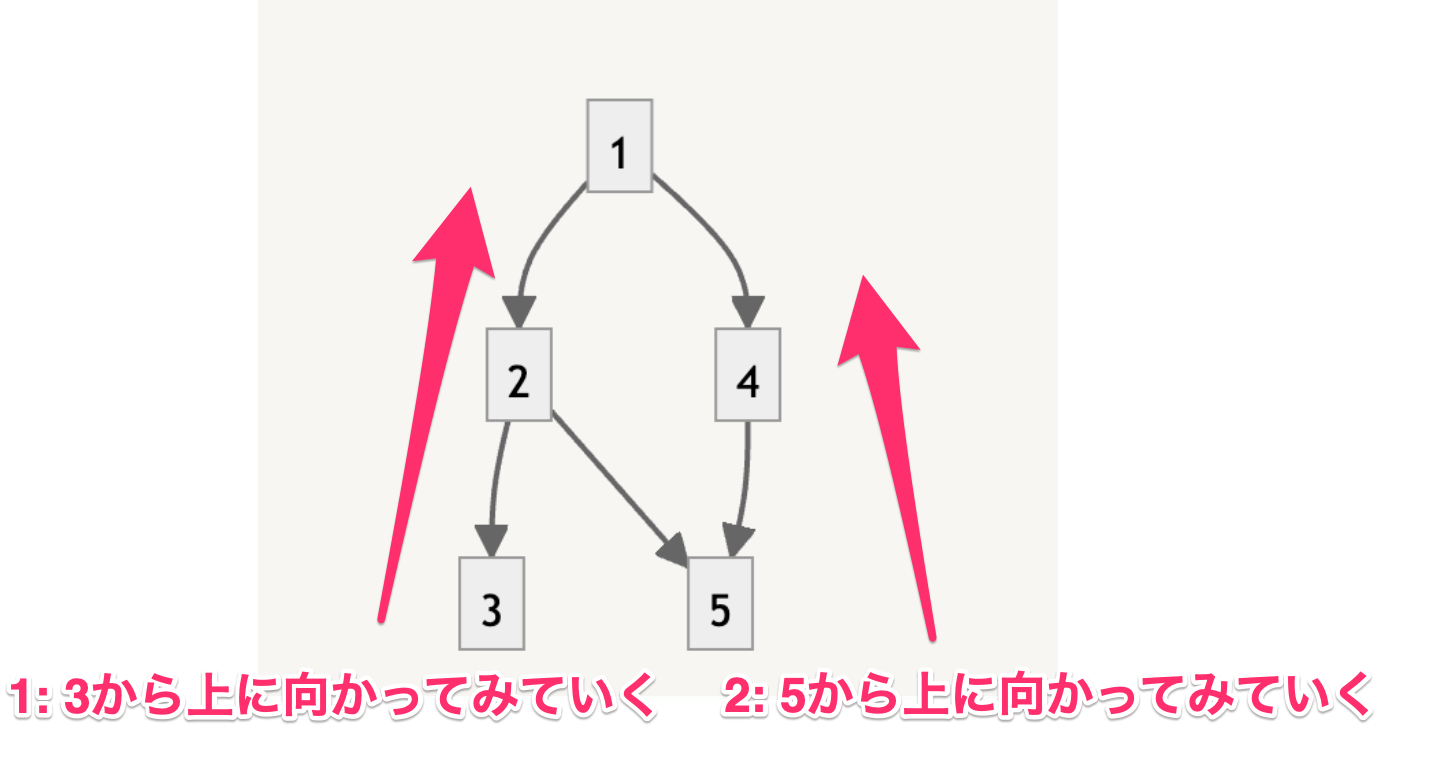
- 厳密に言えば、重複には注意しないとな
- 今回だと3,2って見た後にまた5から上がっていくと4だけじゃなくてまた2を見ることになりそうだ
- うーん。子から親に向かっていくようなアルゴリズムってどっかで見たんだよなぁ
- ・・・待って。これ深さ優先探索じゃないか!?
- 深さ優先探索の帰り道ってこんな感じだよな
- これ、前なんかの問題で似たような類題をやったことあるぞ!
- ※ E - Subtree K-th Maxの問題でした
- これは来たw解けますわ。深さ優先探索する時に2回目に訪問するのが復路ですわw
- ※ 解けなかった
というようにテンション上がっていました。
実際に提出したコードと問題点
提出してTLEになってしまったコードがこちらです。
from collections import deque
N = int(input())
parents = []
# まずグラフを作る
G = [[] for _ in range(N+1)]
for i in range(N):
C, *P = map(int, input().split())
if i == 0:
parents = P[:]
G[i+1] = P[:]
# DFSで子から親に向かってリストに詰める
# 2回目の訪問(子から親)と判別できるようにキューに必要な情報を詰めていく
# (今いるノード,親のノード,頂点の訪問回数)
q = deque([(1, 0, 1)])
ans_list = []
while q:
now, parent, cnt = q.pop()
# ここですでに答えに詰めているノードはスキップ
if now in set(ans_list):
continue
# 1回目の訪問
if cnt == 1:
q.append((now, parent, 2))
for to in G[now]:
# 注: 今回子から親への経路を保持していないので無駄実装
if to == parent:
continue
q.append((to, now, 1))
else:
for to in G[now]:
# 注: 今回子から親への経路を保持していないので無駄実装
if to == parent:
continue
# 順番を保ったまま重複を除く
# 注: 問題点
if to not in set(ans_list):
ans_list.append(to)
print(*ans_list, sep=' ')
上がTLEになってしまうコードですね。
問題点は以下の部分です。
if to not in set(ans_list):
ans_list.append(to)
すでに見た本ならスキップみたいなノリで書いているのですが、これだと計算量が多くなっています。
本来やりたいことは「答えに詰めているか」ではなく「すでに訪問しているノードか」のはずです。
ということで、すでに2回訪問しているノードかを判定するための配列を用意することで、O(1)で判定できるようになり、以下のコードでACを得ることができました。
from collections import deque
N = int(input())
# 注: いらない変数です。無駄実装です。
parents = []
# まずグラフを作る
G = [[] for _ in range(N+1)]
for i in range(N):
C, *P = map(int, input().split())
if i == 0:
parents = P[:]
G[i+1] = P[:]
# DFSで子から親に向かってリストに詰める
# 2回目の訪問(子から親)と判別できるようにキューに必要な情報を詰めていく
# (今いるノード,親のノード,頂点の訪問回数)
q = deque([(1, 0, 1)])
ans_list = []
visited = [False] * (N+1)
while q:
now, parent, cnt = q.pop()
# ここですでに答えに詰めているノードはスキップ
if visited[now]:
continue
# 1回目の訪問
if cnt == 1:
q.append((now, parent, 2))
for to in G[now]:
q.append((to, now, 1))
else:
for to in G[now]:
if visited[to]:
continue
visited[to] = True
ans_list.append(to)
print(*ans_list, sep=' ')
まとめ
- C問題まで解きたいマンなので目的は達した
- 深さ優先探索って気づけたのはよかったし、実装の方向はよかった
- 解けなかったのは悔しいけど、実装の方針的には合っていたので少しづつ実力がついてきたみたい
コンテストに出るまでのコンディションも良かったし、問題も苦手な類が少なかったのでその辺りの運もありそうです。
これからもゆるく趣味を続けたいと思います!
最後まで読んでいただいた方、本当にありがとうございました!